
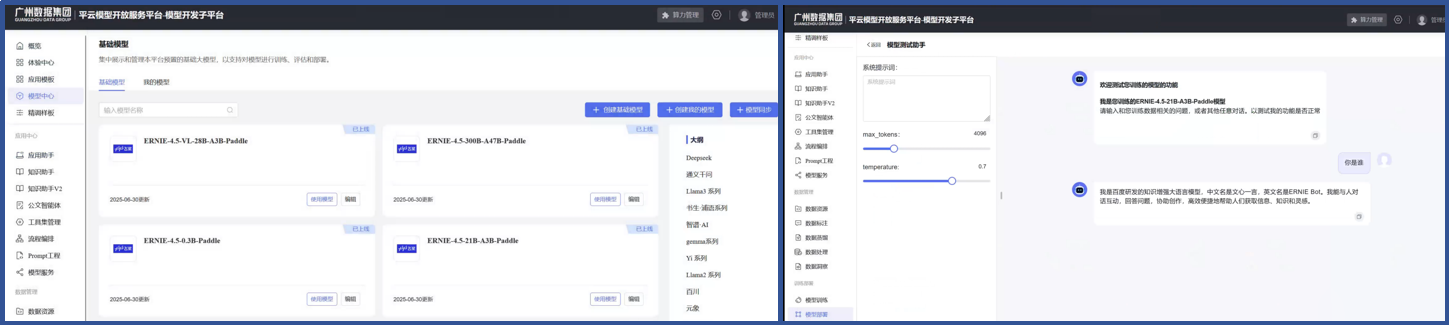
文心大模型4.5系列开源模型简介
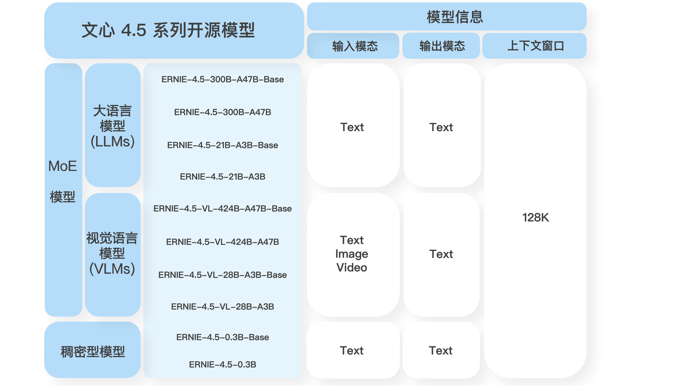
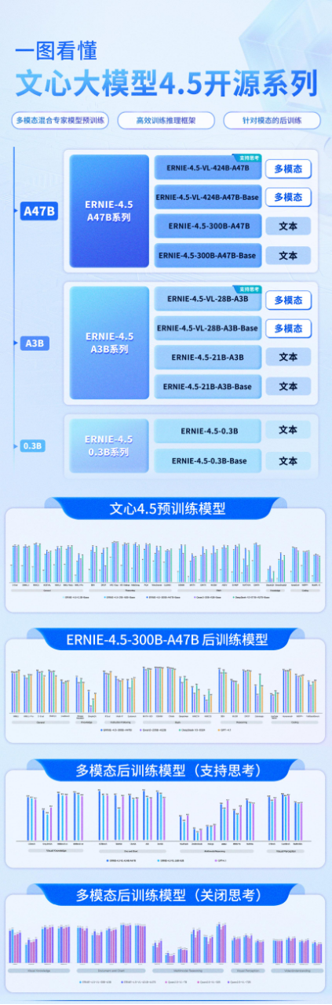
本次开源的文心大模型4.5系列在三大维度实现升级:
● 多模态混合专家模型预训练:文心4.5通过在文本和视觉两种模态上进行联合训练,更好地捕捉多模态信息中的细微差别,提升在文本生成、图像理解以及多模态推理等任务中的表现。
● 高效训练推理框架:通过节点内专家并行、显存友好的流水线调度、FP8混合精度训练和细粒度重计算等多项技术,显著提升了预训练吞吐。基于飞桨框架,文心4.5在多种硬件平台均表现出优异的推理性能。
● 针对模态的后训练:为了满足实际场景的不同要求,文心团队对预训练模型进行了针对模态的精调。其中,大语言模型针对通用语言理解和生成进行了优化,多模态大模型侧重于视觉语言理解,支持思考和非思考模式。
广州算力中心:与优质大模型同行,助力千行百业
人工智能技术发展迅猛,广州算力中心紧跟潮流,不断提升AI领域硬实力。我们期待与更多生态伙伴合作,不管是锐意创新的企业、底蕴深厚的高校,还是追求卓越的科研机构,均可依托广州算力中心这一强大的赋能平台,便捷稳定地调用文心大模型,开展全面细致的测试,实施精准深入的训练,全方位挖掘模型潜力。
<广州人工智能公共算力中心-平云模型开放服务平台>
登录广州人工智能公共算力中心官网,即刻文心大模型的强悍推理能力,还能一键调用160+款开源模型,轻松玩转AI创新。合作里,我们会全程支持,帮大家破除技术难题,激发创新灵感,加快各行业的数字化、智能化升级。快来广州算力中心,和我们一起描绘智能时代的美好蓝图,向着更智能、更高效的未来进发!
电话:15078300275
邮件:aipcc-gz@grg.net.cn
地址:广东广州市天河区平云路163号




